Getting Business Value From AI: Running AI Projects



With the project team in place, it is worth noting that AI projects are a slightly different beast and require special treatment over and above regular project management best practice. The key difference is that there are a greater number of uncertainties relative to a typical software project, such as whether the data is available, whether it contains the patterns and behaviours which were expected and whether this is sufficient for building the solution (including any underlying AI models). As such, care needs to be taken to ensure that project managers and any relevant stakeholders are aware of this, so that there are no nasty surprises, and that appropriate timeframes and contingencies are incorporated. For more information about managing AI projects, see Managing Machine Learning Projects: From Design to Deployment. https://www.amazon.co.uk/Managing-Machine-Learning-Projects-Deployment/dp/163343902X
Throughout this series of articles, I have coflated the different flavours of AI (Gen AI and ‘old’ AI, including machine learning/ML, natural language processing/NLP, etc.), since the AI components of a solution generally all fit a similar pattern, specifically, that of a defined input from the business (e.g., structured data or prompt text) resulting in a particular output (e.g., predicted numeric data or generated text), which flows through the rest of the solution and ultimately into the business.
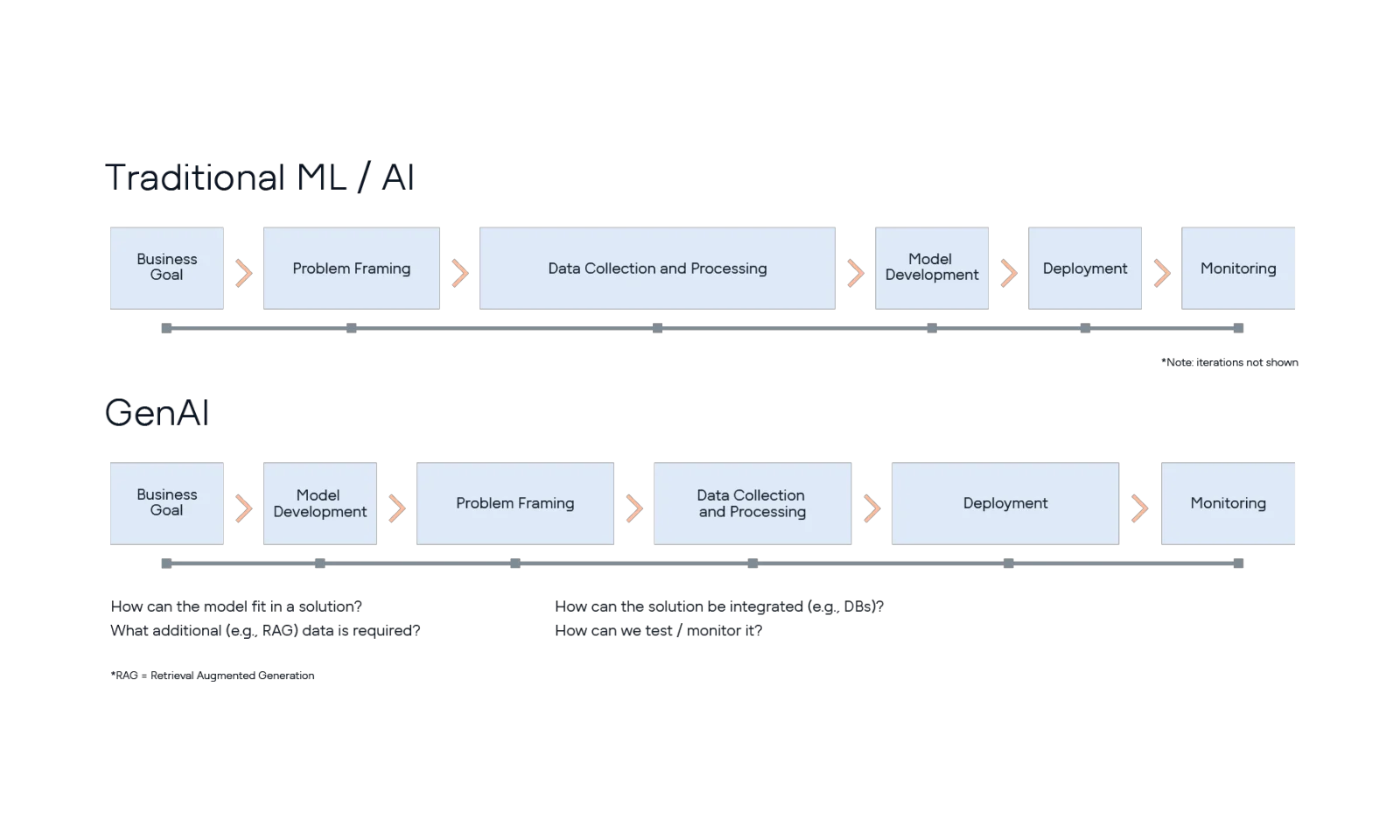
However, at this point, it is worth taking a brief interlude to highlight the main difference between Gen AI and other varieties, in particular how the model is developed, since it has major implications for the practical stages of developing and implementing an AI solution.
Traditional AI models, such as those developed in ML projects, take a set of training data (often sourced for this particular purpose) and combine it with an algorithm selected for this same purpose, which results in a trained model specific to the data it has been trained on and the application it has been developed for. Going back to the example of identifying customer churn in the previous article, here the data would be specific to that organisation, with the resulting model tailored to that particular use case.
This description glosses over the details of the process of developing an ML model with which many data scientists and ML engineers are all too familiar. For example, one of the first hurdles that they face will be to get hold of the data required for training a model which can often be a challenge in many organisations. Subsequent steps require exploration of the data, identifying appropriate algorithms and approaches and then training and testing the various iterations of the model. All of this can be time-consuming and tedious, often viewed as an art as well as a science, and - worst of all - the data scientist may discover that there is no signal in the data and that it is impossible to build a model to predict the phenomenon that they were expecting to be able to predict!
However, one of the advantages of traditional AI approaches, such as ML, is that there are (relatively) mature and well-defined processes for developing and testing these models and then deploying them into production (for example this paper https://research.google/pubs/machine-learning-the-high-interest-credit-card-of-technical-debt/ from 2014 was something of a ‘call to arms’ for many practitioners in this area). This is not to say that it is without challenges, and there are plenty of uncertainties (certainly relative to regular software projects), but once the model has been properly tested and approved (i.e. it ‘works’), it can then be deployed, following the various best practice recommendations from MLOps.
On the other hand, generative AI approaches start with a general, pre-trained model (large language model, or more generically termed ‘foundation model’), which is then customised to the particular application by means of supplying different information in the prompt (e.g., the wording of the prompt, specific organisational information), in order to manipulate the output of the foundation model in the desired way.
Again, this high-level description misses out much of the detail. For example, the phase of starting with a foundation model will likely involve iterating over different pre-trained models as well as prompts (and contextual data) to get a sense of whether the idea might be possible. Then there might be a phase of problem framing to map the solution back to the business problem followed by the data collection and processing. Essentially, it is easier to rapidly prototype a solution, since the need for training data has been removed, but the problem framing to map the solution to the business may be less easily understood, may need to be bespoke to that particular solution and therefore take longer. In a similar way, the testing of model/solution performance may again be less well understood (unlike the standard metrics used in ML, such as precision or recall), and therefore will also take longer; the same too for deployment and monitoring, again because of the more bespoke nature of the solution.
All of this assumes that the Gen AI solution is using an off-the-shelf foundation model, such as OpenAI’s GPT-4.5, Google’s Gemini 2.5 or DeepSeek’s R1, which can be queried like an API by the developer. Although foundation models can be built from scratch, we expect that this is not going to be something that most organisations would consider doing; fine-tuning an existing model would perhaps be more likely, but still relatively uncommon (e.g., https://www.kadoa.com/blog/is-fine-tuning-still-worth-it)
Why is this detour into the differences between ‘old’ AI and Gen AI important? I believe it is for at least two reasons: Firstly, it is important to know where the different challenges may occur and therefore which parts may take more time in a project. Looking at Figure 1, reveals where more time and resources – both internal project team as well as external stakeholder – might be required across the different types of AI projects.
Secondly, with rapid prototyping relatively easy in Gen AI projects, issues with understanding and accessing the organisation’s data – long a bugbear in traditional AI projects – are only uncovered at a later stage, such as after the initial prototypes have been developed. Indeed, it may be that challenges with mapping the AI prototype element into an overall solution that integrates with the business problem and available data result in few projects making it into production and many resulting in failure.
Similarly, bespoke elements of the project may prove difficult, perhaps the most important being the convincing testing of the solution. This is vital to ensure that the organisation is happy for the solution to be deployed into production and accepted to service. Other elements might be the usually more mechanical processes like deployment and monitoring. Building assurance that these steps are possible before engaging senior stakeholders and funding a project is essential.
To summarise,
whereas traditional AI approaches have a concentration of effort around the early stages of sourcing the data and building the model (often taking longer than desired to get to this point), Gen AI approaches can show rapid early progress in prototyping, but potentially require greater investment in the later stages of a project. As always, these are generalisations but hopefully illustrate overall patterns of these projects.
Going back to the starting point for this series, that of ROI apparently dropping for AI projects. Perhaps this is tied in with the rise in Gen AI projects and the ability to rapidly prototype, even before engaging with the business? Could this be leading to a misallocation of resources as compelling demos that cannot be converted into useful applications win funding and attention at the expense of less ambitious and attractive projects that are in fact more practical and useful? This, of course, is pure speculation on my part, but the answer remains the same, and is the key takeaway from this series of articles regardless of the flavour of AI, namely to engage with the business first to understand the business need and the surrounding context for any potential solution that we plan to build.
In conclusion,
across this series, I have highlighted some of the steps that those embarking on a typical AI project will need to take, aside from the task of actually building the AI model. These articles have focused in particular on understanding the business problem, speaking to stakeholders, mapping the solution to the business logic, and practicalities of running an AI project. Throughout, the focus has been to ensure that the AI project creates value for the business, which I hope will provide a useful starting point for others.







